


“Big data” is definitely one of the biggest tech buzzwords of the 21st century. In fact, one of the TED Talks I watched recently (“The human insights missing from big data” by Tricia Wang, September 2016) even hailed big data as the modern “oracle”…a replacement of the literal oracles that were once considered divine, like the Oracle of Delphi in Ancient Greece.
I’m sure a lot of people must be thinking: wow, how far we’ve come, from taking advice from a woman in trance to actual real data that’s a lot less likely to fail us. But the truth is, big data isn’t as reliable as we seem to think it is. While big data is a 122 billion dollar industry, it remains that 73% of big data projects are unprofitable. This is because most real-world systems are not as neatly “contained” as many quantitative models suggest. As Wang herself puts it: “big data alone increases the chance of missing something, while giving the illusion that we know everything.”
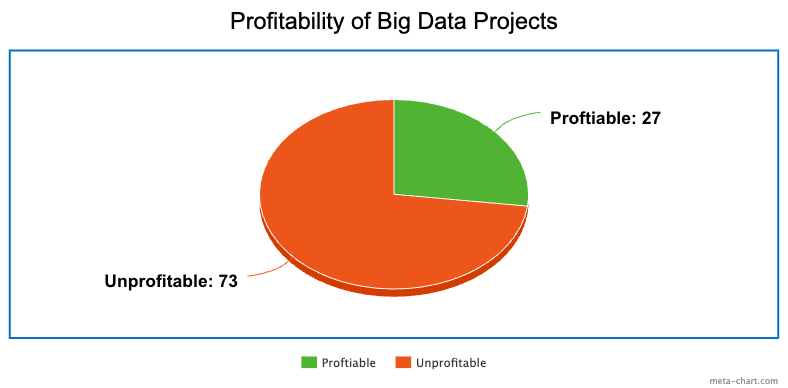
So what does this mean for data science? Is it worth continuing development in data, sometimes at the cost of billions of dollars? The answer: yes. Because as Wang explains, there is a whole other side of data that is often overlooked, but actually incredibly insightful, called “thick data,” and combining it with pre-existing big data can increase data’s predictive accuracy and profitability in decision-making.
But what is “thick data” and how is it different from “big data”? Thick data is qualitative, observational, and emergent, whereas big data is quantitative, algorithmic, and large-scale.
We as humans have a “quantification bias,” meaning we tend to value the measurable (or the quantitative) over the immeasurable (or the qualitative). Put simply, quantifying is addictive. But it’s time for us to realize that quantification alone does not give us the full picture. Without qualitative observation, our data lacks context and human-naturedness. So as data scientists, we need to push past our obsessions with numbers to consider big data and thick data together. Think of it this way:
Complete Picture = Big Data + Thick Data
The efficacy of this concept is seen clearly in the success of Netflix’s user-tailored movie/show recommendations. At first, Netflix relied solely on big data, using complex quantitative models to try and predict content that a user would most likely enjoy. They did okay back then. But do you know when their viewership and subscription (and therefore their stock) showed huge increases? After they took into consideration the thick data observation that human beings like to binge-watch. Therefore, instead of recommending content based purely on the patterns in a user’s preferences, Netflix also began recommending content that when put together is easily “binge-able.” So not only will you be recommended content you like, you’ll also be recommended a “path” for a movie/show marathon. That’s why as soon as you finish a movie or show, Netflix is immediately trying to get you to watch similar movies and shows…it’s meant to keep you sitting there for longer.

Isn’t that a brilliant strategy? I mean, what are chances that quant models alone would be able to capture that exact observation? Not likely, not when binge-watching is such a human thing to do. And that’s exactly why we need to start using thick data hand-in-hand with big data: to frame data in more meaningful contexts and create more profitable results.

Leave a comment